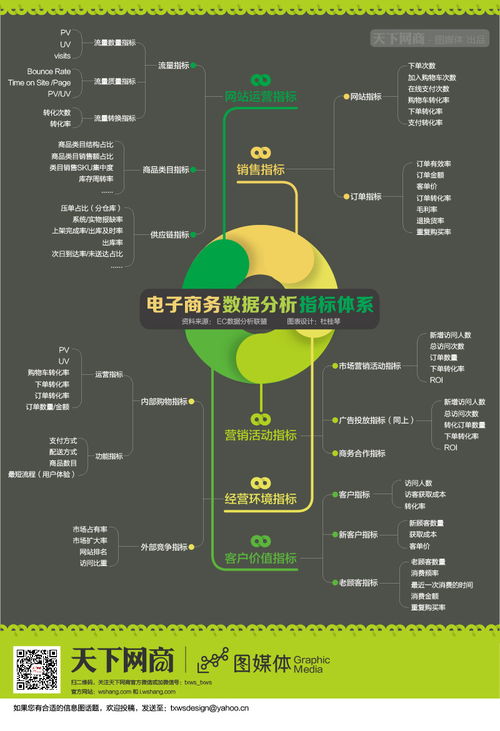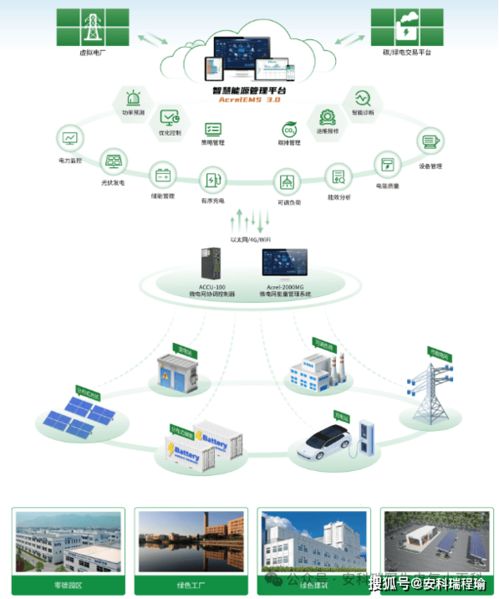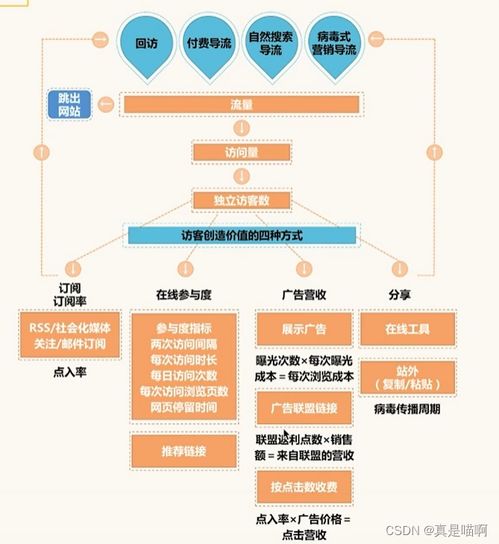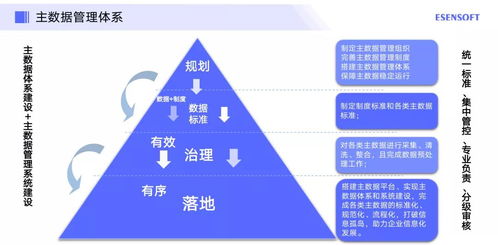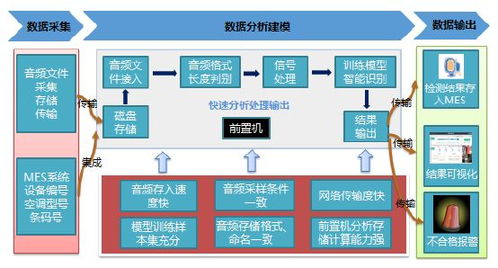
在工業4.0與智能制造浪潮下,人工智能(AI)正逐步滲透到工業設備的故障診斷領域,成為提升生產效率和保障設備穩定性的關鍵工具。盡管技術前景廣闊,當前的AI故障診斷在實際應用中仍面臨諸多挑戰,尤其在數據處理層面,其發展狀態被形象地比喻為“雞尾酒療法”階段——即依賴多種方法的混合與試錯,而非系統化的精準解決方案。
一、AI故障診斷的潛力與現狀
AI技術,特別是機器學習和深度學習,能夠通過分析設備運行數據(如振動、溫度、壓力等傳感器信號),識別異常模式并預測潛在故障。這相比傳統基于規則或經驗的診斷方法,具有更高的準確性和實時性,可有效減少停機時間、降低維護成本。目前,許多工業企業已開始試點AI診斷系統,應用于風電、軌道交通、數控機床等領域,初步驗證了其技術可行性。
二、數據處理:當前的核心瓶頸
AI故障診斷的落地并非一帆風順,其核心挑戰集中于數據處理環節,這主要體現在以下幾個方面:
- 數據質量參差不齊:工業現場環境復雜,傳感器數據常受噪聲、缺失或異常值干擾,導致“垃圾進、垃圾出”現象,影響模型可靠性。
- 數據標注困難:故障樣本稀少且標注依賴專家經驗,成本高昂,使得監督學習模型訓練面臨數據不均衡問題。
- 多源異構數據整合:設備數據來自不同品牌、類型的傳感器,格式多樣且時序不一致,如何有效融合成為技術難點。
- 實時處理需求高:工業場景要求低延遲響應,但傳統數據處理流程(如清洗、特征提取)耗時較長,難以滿足實時診斷需求。
這些挑戰迫使企業采用“雞尾酒療法”,即混合使用多種數據處理技術(如濾波去噪、遷移學習、生成對抗網絡生成合成數據等),通過試錯尋找臨時解決方案,而非構建標準化、可擴展的數據管道。這種模式雖能緩解燃眉之急,卻導致系統復雜、維護成本上升,且難以規模化推廣。
三、突破方向:邁向系統化數據處理
為擺脫“雞尾酒療法”的局限,行業需從以下方面尋求突破:
- 標準化數據采集與治理:制定統一的數據接口和存儲規范,結合邊緣計算預處理原始數據,提升數據質量基礎。
- 發展弱監督與無監督學習:利用異常檢測、聚類等方法減少對標注數據的依賴,同時探索聯邦學習以保護數據隱私。
- 構建工業知識圖譜:整合設備結構、維修記錄等先驗知識,增強數據語義理解,提升診斷可解釋性。
- 云邊端協同架構:在邊緣側進行實時初步處理,云端負責模型訓練與優化,平衡效率與精度需求。
四、展望:從“混合試錯”到“精準醫療”
隨著工業物聯網(IIoT)的普及和5G技術的應用,數據獲取將更加全面高效。AI故障診斷有望從當前的“雞尾酒療法”過渡到“精準醫療”階段——即基于高質量、標準化數據,構建自適應、可解釋的診斷模型,實現個性化預測與維護。這不僅需要技術創新,還需行業協作推動標準制定與生態建設。
AI在工業設備故障診斷中的應用仍處于成長期,數據處理是關鍵突破口。只有克服數據瓶頸,才能釋放AI的真正潛力,推動智能制造向更高階的自主化與智能化邁進。